현 시점(2026-07-05 기준)에서 Test AUC 0.6679 / LogLoss 0.6462 / overfit_gap 0.0251 / Brier 0.2279 / ECE 0.012 (Test n = 10,792, 트리 600, 보정 = beta calibration).
⚠ 누출 정직화 이력: (1) 2026-06-22 — 동종족(PvP/TvT/ZvZ) 매치업의 종족·맵 방향 피처가 결과 라벨과 완벽히 일치하는 라벨 누출을 발견·수정(이전 AUC ~0.71대는 이 누출로 부풀려진 값). (2) 2026-07-05 — BT OOF의 미러쌍 누출(한 경기의 승자/패자 2행이 교차검증 fold에 분리되어 준 in-sample화)을
GroupKFold(match_id)로 추가 폐쇄. 두 번의 누출 제거 후에도 hold-out 성능이 이 수준을 유지한다는 것은, 제거된 신호가 일반화에는 기여하지 않고 지표만 부풀렸음을 뜻합니다. 상세는 학습 히스토리 참조.
각 지표가 의미하는 바와, 왜 이 수준이 본 데이터 regime의 합리적 천장인지 정리한다.
AUC — 판별력
무작위로 뽑은 "실제 승자"와 "실제 패자" 한 쌍에서 모델이 승자에게 더 높은 승률을 부여할 확률이다.
AUC 0.5 = 동전 던지기와 같은 무작위 수준(승패를 전혀 구별하지 못함), AUC 1.0 = 완벽한 서열 분리(모든 승자를 모든 패자보다 항상 높게 점수 매김).
순위 지표이므로 확률값 절대 크기가 아니라 "누가 이길 가능성이 더 큰지"의 서열만 본다.
- 현 시점 BT + LightGBM AUC: 0.6679 (누출 2회 제거 후 정직값 — 옛 0.71대는 폐기)
왜 이 값을 사실상 천장으로 보는가
-
피처 regime의 한계 — 학습 데이터를 통해서는 플레이어의 승/패·종족·맵·날짜를 알 수 있고, 이를 통해 40개 피처가 파생되었다.
플레이어의 심리 상태, 경기 당일 컨디션, 순간 교전능력 등의 정성적 퍼포먼스는 계량화, 정량화가 불가능에 가까워 제외되었다.
리플레이를 통한 플레이어의(e)APM/빌드오더 상성 등과 같은 외부 신호도 도입되지 않았고, 도입하기도 어렵다.
복합 피처 등을 통해 여러 시도를 해봤으나, 유의미한 AUC 증가가 계측되지 않았고, 피처 복잡성에 의한 악영향이 발생했다. 40개가 현 시점에서 최적이라 판단됐다.
-
내부 최적화의 수렴 — 하드 라벨3 전환·main-CV GroupKFold4·h2h 임계값 sweep·expected_win_rate 중복 제거 등 다단계 ablation5에서 하드 라벨 전환과 expected_win_rate 중복 제거는 채택, main-CV GroupKFold·h2h sweep은 Test AUC 유지/하락으로 기각됐다. (별개로 BT OOF 미러쌍 누출은 2026-07-05 GroupKFold로 폐쇄 — 위 Data Leakage 절 참조.) 현 데이터 내부에서 추가로 짜낼 여지는 거의 남아 있지 않다.
- 도메인 상식 — 외부 신호 없는 팀/개인 스포츠 승률 예측에서 AUC 0.72대는 통상 "의미 있는 판별력의 상한"으로 간주된다.
억지로 높이면 어떻게 되나
트리 개수를 늘리고 정규화를 풀면 Train AUC는 0.80 이상으로 끌어올릴 수 있다. 그러나 이렇게 올린 Train AUC는 Test AUC 상승으로 이어지지 않는다 — 오히려 Test AUC는 동일 수준에 머물거나 하락하고, overfit_gap만 벌어진다. 즉 학습 데이터를 외운 결과일 뿐 새 경기에 대한 예측력은 전혀 개선되지 않는다. 결과적으로 Train AUC를 0.80까지 끌어올리는 것은 무의미하다.
무엇으로 실력을 나누는가 — 변별력의 구조적 차이
판별력이 낮아 보이는 데에는 모델 이전의 더 근본적인 원인이 있다: 무엇을 기준으로 두 선수를 비교하는가이다. 같은 경기라도 공개 정수 티어(공인티어) 로 나누느냐, 데이터 기반의 연속 실력값으로 나누느냐에 따라 변별력이 크게 갈린다.
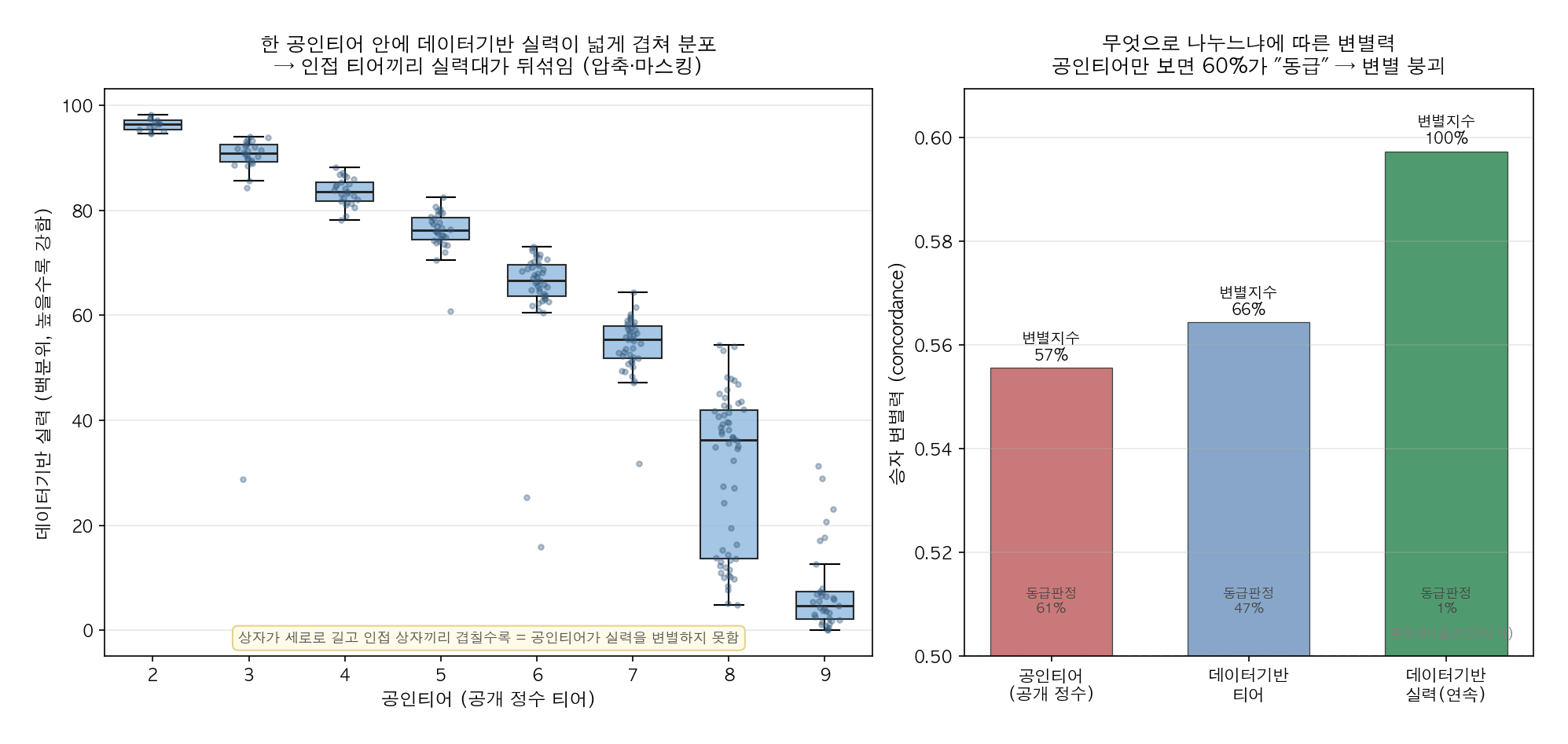
- 왼쪽 — 하나의 공인티어(공개 정수 티어) 칸 안에, 데이터 기반 실력(백분위)이 넓게 겹쳐 분포한다. 특히 인접한 티어끼리 실력대가 상당 부분 뒤섞인다. 정수 티어가 여러 실력대를 한 칸에 뭉개는 압축·마스킹 현상이다.
- 오른쪽 — 그 결과 실제 경기의 승자를 얼마나 가려내는지(변별력)가 갈린다. 공인티어만 보면 매치의 약 60%가 "동급"으로 판정되어 변별 자체가 불가능해진다. 반면 데이터 기반의 연속 실력값은 이 미세한 차이를 그대로 살려 가장 높은 변별력을 낸다.
즉 공개 정수 티어로 매칭 풀을 나누면, 실력 차이의 표현이 눌려(압축) 점수 변별이 구조적으로 낮아진다. 본 예측 엔진이 (정수 티어가 아니라) 연속적인 데이터 기반 실력값을 축으로 삼는 이유가 여기에 있다 — 티어가 "같다"고 뭉뚱그리는 구간에서도 실제 실력차를 읽어내 예측에 반영한다. 위 AUC/LogLoss 천장 논의는 이 연속 실력값을 이미 쓴 상태의 값이며, 만약 공개 정수 티어에만 의존했다면 변별력은 더 크게 무너졌을 것이다.
참고: 위 그림은 상대적 구조(백분위·변별지수)만 나타내며 개별 절대 점수·순위는 비노출한다.
LogLoss — 확률값 자체의 정밀도
예측 확률 $p$와 실제 결과 $y$에 대해
$$\mathrm{LogLoss} = -\frac{1}{N}\sum_i \bigl[\, y_i \log p_i + (1 - y_i)\log(1 - p_i)\,\bigr]$$
AUC가 순위만 보는 지표라면 LogLoss는 확률값 자체의 정확성을 본다. 0.9로 예측했는데 패배하면 큰 페널티를 먹는다.
- 상수 모델(항상 0.5 예측)의 LogLoss ≈ 0.693
- 본 모델 Test LogLoss 0.6462. 이는 베팅시장이 존재하는 프로스포츠 상위 공개 모델(NBA·NFL ~0.58-0.62, 베가스 클로징 라인 ~0.60)보다 명확히 높다. 이유는 성능 부족이 아니라 도메인의 환원 불가능한 불확실성이 더 크기 때문이다 — 외부 신호원(리플레이 e/APM·빌드오더·방송 메타)이 전무하고, 비슷한 실력대 스트리머 간 접전 비중이 커서 base 불확실성이 거의 최대(0.5)다.
- 핵심: 이 LogLoss는 이미 바닥에 붙어 있다. 아래 Brier 분해에서 보정 오차(reliability)는 0.0003, "이 판별력에서 완벽 보정 시 도달 가능한 LogLoss 하한 ≈ 0.6458"과의 여백은 단 0.0004다. 즉 재보정·재튜닝으로 짜낼 여지는 사실상 0이고, LogLoss를 더 내리려면 판별력(resolution) 자체를 올려야 하며 그것은 새 외부 신호원 없이는 불가능하다.
왜 더 낮아지기 어려운가
LogLoss의 이론적 하한은 데이터 자체의 환원 불가능한 불확실성(irreducible error)이다. 접전 경기(0.3~0.7 구간)가 많으면 어떤 모델도 LogLoss를 낮출 수 없다. 보정 곡선 하단의 예측 확률 분포를 보면 본 데이터는 이 구간에 집중되어 있다 — 이것이 LogLoss의 자연스러운 바닥을 높인다.
극단 확률 남발의 함정
0.95, 0.05 같은 극단 확률을 남발하면 맞은 경기에서는 LogLoss가 극적으로 내려가지만, 한 번이라도 틀리면 LogLoss가 발산($\log 0 = -\infty$)한다. 평균적으로는 오히려 악화된다.
LogLoss는 strictly proper scoring rule에 해당하므로, 기대 손실을 최소화하는 유일한 최적 전략은 모델이 실제로 믿는 사후 확률을 그대로 출력하는 것이다. 자신의 믿음을 초과한 확신은 정답과 오답 사이의 벌점 구조를 비대칭적으로 증폭시켜 기대 손실을 체계적으로 악화시킨다. 즉 과도한 자신감은 단순한 스타일 문제가 아니라 scoring rule 관점에서 수학적으로 지배 전략이 아니다.
과적합 — overfit_gap
overfit_gap = Train AUC − Test AUC
모델이 학습 데이터를 외웠는지, 일반화했는지의 단순 지표.
- 본 모델: 0.0251 (통상 안전선 0.03 이하)
- 이 gap 내에서는 "미래 데이터에서도 Test 성능이 유지된다"고 기대할 수 있다.
왜 0.03을 기준으로 보는가
gap이 0.03을 넘으면 모델이 학습 데이터의 노이즈까지 학습했다는 신호다. 이 경우 새 시즌(버전)·새 선수 유입 시 성능이 떨어진다 — 매일 새 경기가 들어오는 본 도메인에서는 치명적이다. 현 모델의 gap 0.0251은 안전선 이내다.
Data Leakage — 데이터 누출
"실전에서 절대 볼 수 없는 정보"가 학습 중에 모델 눈에 들어가 Test 성능이 부풀려지는 현상이다. 본 데이터의 고유 위험은 매치 미러링이다.
본 데이터의 고유 위험
한 경기(match)가 두 행으로 저장된다 — A 관점과 B 관점. outcome은 서로 0/1 미러링이고, 피처도 A/B가 교차된 값이다. TimeSeriesSplit으로 쪼개면 같은 match의 A행이 Train에, B행이 Test에 갈 수 있다 — 이론적으로는 누출 경로다.
어디에 GroupKFold가 필요한가 — BT OOF (2026-07-05 채택)
미러링 누출의 진짜 위험 지점은 BT 레이어의 BT_base_prob_A OOF 예측이다. BT 모델은 한 경기를 승자 관점(y=1)과 패자 관점(y=0) 두 행으로 학습하는데, 절편 없는(fit_intercept=False) 로지스틱 회귀에서 이 두 행은 수학적으로 완전 중복(피처가 부호만 반전)이다. cross_val_predict가 shuffle-KFold로 이 미러쌍을 서로 다른 fold에 분리하면, 승자행의 OOF 예측을 낼 때 그 짝(패자행)이 학습 fold에 들어가 사실상 자기 자신을 본다 → OOF가 준 in-sample이 되어 BT_base_prob_A가 상방 편향된다.
해법: BT OOF를 GroupKFold(match_id)로 재구성해 미러쌍을 반드시 같은 fold에 묶었다. 이러면 승자행 예측 시 그 짝이 함께 held-out 되어 진짜 out-of-sample이 보장된다.
| 이전 (shuffle-KFold OOF) | GroupKFold OOF (현) | |
|---|---|---|
| Test AUC | ~0.674 | 0.6679 |
| overfit_gap | ~0.020 | 0.0251 |
누출 채널을 닫았는데 hold-out AUC가 사실상 유지됐다 — 즉 미러쌍이 넘겨주던 신호는 일반화에 기여하지 않고 OOF 피처만 부풀리던 것이었다. 참고로 과거(2026-04) main-CV 자체에 GroupKFold를 적용한 실험은 당시 데이터 regime에서 gap이 악화되어 보류됐으나, 그것은 여기서 닫은 BT-OOF 채널과는 다른 지점이었다. 최종 서빙 BT 모델(lr_final)은 이 변경과 무관하게 불변이다.
보정 — Brier / ECE
- Brier score1 = 0.2279 — baseline(항상 0.5) 0.25 대비 개선, 외부 신호 없는 본 regime에서 양호
- ECE (Expected Calibration Error)2 = 0.012 — 사용자 노출 안전선 0.05 이하. 2026-06-03 sigmoid → beta calibration 교체로 65-75% 과신과 80%+ 과소를 동시에 잡는 비대칭 보정을 채택(상세 보정 곡선).
AUC는 순위만 본다. 모든 예측을 [0, 1] 대신 [0.48, 0.52] 범위로 압축해도 AUC는 동일하다. 그러나 확률을 사용자에게 "승률 %"로 노출하는 순간, 보정되지 않은 확률은 오해를 일으킨다. Brier와 ECE는 바로 이 지점 — 모델이 출력한 숫자가 실제 관측 빈도와 얼마나 일치하는가 — 를 점검하기 위해 필요하다. 자세한 시각적 해석과 구간별 수치는 보정 곡선 페이지에서 다룬다.
종합
| 지표 | 값 | 평가 |
|---|---|---|
| Test AUC | 0.6679 | 외부 신호 없는 현 regime의 상한 근접(누출 2회 제거 후 정직값) |
| Test LogLoss | 0.6462 | 베팅시장 프로스포츠(~0.60)보다 높음 — 외부 신호 부재·접전 비중이 큰 도메인의 환원불가 불확실성. 보정 여백 0.0004로 이미 하한 |
| overfit_gap | 0.0251 | 안전선(0.03) 이하, overfit-aware 선택으로 수렴 |
| Brier / ECE | 0.2279 / 0.012 | beta calibration |
현재 모델은 주어진 데이터로 구성 가능한 표현력의 천장에 근접해 있다. 내부 최적화만으로 유의미한 추가 상승은 기대하기 어렵고, 억지 피팅은 네 지표 중 어느 하나를 반드시 악화시킨다. 다음 단계의 의미 있는 개선은 외부 신호원의 표본 누적 후 재평가하는 것이 합리적이다 — 상세는 로드맵 참조.
-
Brier score — 예측 확률 $\hat p$와 실제 라벨 $y \in {0, 1}$의 제곱 오차 평균: $\frac{1}{N}\sum (\hat p_i - y_i)^2$. 0에 가까울수록 좋다. LogLoss처럼 strictly proper scoring rule이지만 발산하지 않고(유계) 벌점이 선형적으로 완만해, 평균적인 확률 정확도를 안정적으로 보여준다. 항상 0.5를 찍는 baseline은 0.25이므로 0.25 미만이면 의미 있는 예측력으로 본다. ↩
-
ECE (Expected Calibration Error) — 예측 확률을 구간(bin)별로 묶어, 각 구간에서 "모델이 말한 평균 확률"과 "실제 승률"의 차이를 샘플 비율로 가중 평균한 지표. 0에 가까울수록 좋다. 예컨대 모델이 "70% 승률"이라고 한 경기들에서 실제로 70%가 이기면 그 구간의 보정 오차는 0이다. AUC·LogLoss가 "얼마나 잘 맞혔는가"를 본다면 ECE는 "모델이 출력한 숫자를 그대로 % 승률로 믿어도 되는가"를 측정한다. 통상 0.05 이하면 사용자 노출에 안전한 보정 수준으로 간주된다. ↩
-
하드 라벨(hard label) — 학습 목표값을 ${0, 1}$ 같은 확정 이진값으로 주는 방식. 경기 결과의 경우 "A가 이겼다 = 1, 졌다 = 0"으로 표기한다. 반대 개념인 소프트 라벨(soft label) 은 0.7·0.3 같은 확률 형태로 목표값을 주는 방식이다. 본 프로젝트에서는 초기에 BT 기반 확률을 소프트 라벨로 사용했으나, 실제 관측 결과(이겼다/졌다)와의 정합을 위해 하드 라벨 전환을 ablation으로 검증한 뒤 채택했다. ↩
-
GroupKFold — scikit-learn의 교차검증 분할 방식. 같은 그룹(동일
Match number의 A/B 두 관측)에 속한 샘플이 반드시 같은 fold에 묶이도록 분할해 그룹 간 누출을 물리적으로 차단한다. 과거 main-CV 자체에 적용한 실험(2026-04-21)은 gap이 악화돼 보류됐으나, 2026-07-05 BTBT_base_prob_AOOF 계산에 적용해 미러쌍 누출을 폐쇄하고 채택됐다(gap 0.0251 유지). ↩ -
Ablation(어블레이션) 스터디 — "한 요소를 빼거나 바꿔보고 성능이 어떻게 변하는지" 측정하는 실험 기법. 의학의 "변수 제거 실험"에서 유래했다. 모델에 새로운 아이디어를 적용할 때마다 해당 변경만 단독으로 넣고/빼고 비교해, 그 변경이 실제 성능에 기여했는지를 객관적으로 검증한다. 본 프로젝트에서는 하드 라벨 전환·main-CV GroupKFold·h2h 임계값 sweep·expected_win_rate 중복 제거를 각각 따로 실험해, 하드 라벨 전환과 expected_win_rate 중복 제거만 채택하고, 성능이 유지되거나 악화된 main-CV GroupKFold·h2h 임계값 sweep은 기각했다. (BT OOF에 대한 GroupKFold는 별개로 2026-07-05 채택.) ↩