보정(calibration)은 모델이 "70% 승률"이라고 말한 경기 중 실제로 70%가 이기는가를 본다. AUC는 순위만 측정하므로, 확률값 자체를 사용자에게 "승률 %"로 노출하려면 보정이 별도로 필요하다.
왜 굳이 보정을 따로 보는가
AUC만 보는 모델은 "5등이 3등보다 잘한다"만 맞히면 된다. 그러나 본 웹페이지는 예측 결과를 승률 %로 노출한다. 사용자가 "65%"를 보고 기대하는 것은 실제 빈도 65%이지, 내부 점수의 상대 순위가 아니다. 이 기대를 부수지 않으려면 보정이 지표상으로도, 그래프상으로도 확인되어야 한다.
Beta calibration 이 하는 일 (2026-06-03 ~)
LightGBM 원 출력은 확률처럼 생겼지만 실제 빈도와 일치한다는 보장이 없다. 초기에는 Sigmoid (Platt) scaling — 로지스틱 파라미터 $(A, B)$ 2개로 $p = \sigma(A z + B)$ 재매핑 — 을 썼다. 가볍고 단조 변환이라 AUC를 바꾸지 않지만, 대칭형(기울기 하나)이라 보정 곡선의 비대칭 편차를 잡지 못한다. 실제로 2026-06-03 모델은 sigmoid 하에서 65-75% 구간 과신(−4~5%p) + 80%+ 구간 과소(+4%p) 가 동시에 남았다 — 한 방향으로 휜 게 아니라 양끝이 반대로 휜 구조라 단일 기울기로는 둘 다 못 편다.
그래서 beta calibration (Kull et al.) 으로 교체했다. 원 확률 $p$에 대해
$$p_{\text{calibrated}} = \sigma!\big(a\,\ln p \;-\; b\,\ln(1-p) \;+\; c\big)$$
로 재매핑한다 (파라미터 3개, 홀드아웃의 직전 구간[calib]에서 로지스틱 회귀로 적합). $\ln p$ 와 $\ln(1-p)$ 의 계수를 따로 두므로 곡선 양끝의 휨을 비대칭으로 교정할 수 있다. 여전히 smooth·단조 변환(AUC 불변)이고 isotonic 같은 step function이 아니다 — 파라미터형이라 과적합 위험도 작다.
검증(out-of-time hold-out + 5-fold time-CV): ECE 0.0254 → 0.0111, 65-75% gap −3.9/−5.3 → −2.9/−1.8, 80%+ gap +3.8 → +0.8. 모든 구간 ±3%p 이내로 수렴하며 sigmoid를 5-fold 중 4개에서 일관 우위. AUC·Brier 손상 없음. 서빙(프론트 sector9.js)과 파이프라인(model_wrapper.py)이 동일 공식을 적용해 판정동등성 유지.
Brier와 ECE의 역할 차이
- Brier score $= \frac{1}{N}\sum_i (p_i - y_i)^2$. 확률 예측의 평균 제곱 오차. 낮을수록 좋다. 모든 샘플을 동등하게 본다.
- ECE (Expected Calibration Error). 각 bin에서 "평균 예측 확률"과 "실제 승률"의 차이를 샘플 수로 가중 평균한 값. 보정 곡선을 하나의 숫자로 요약한 지표.
Brier는 정확도와 보정을 함께 측정하고, ECE는 보정만 측정한다는 점에서 보완적이다.
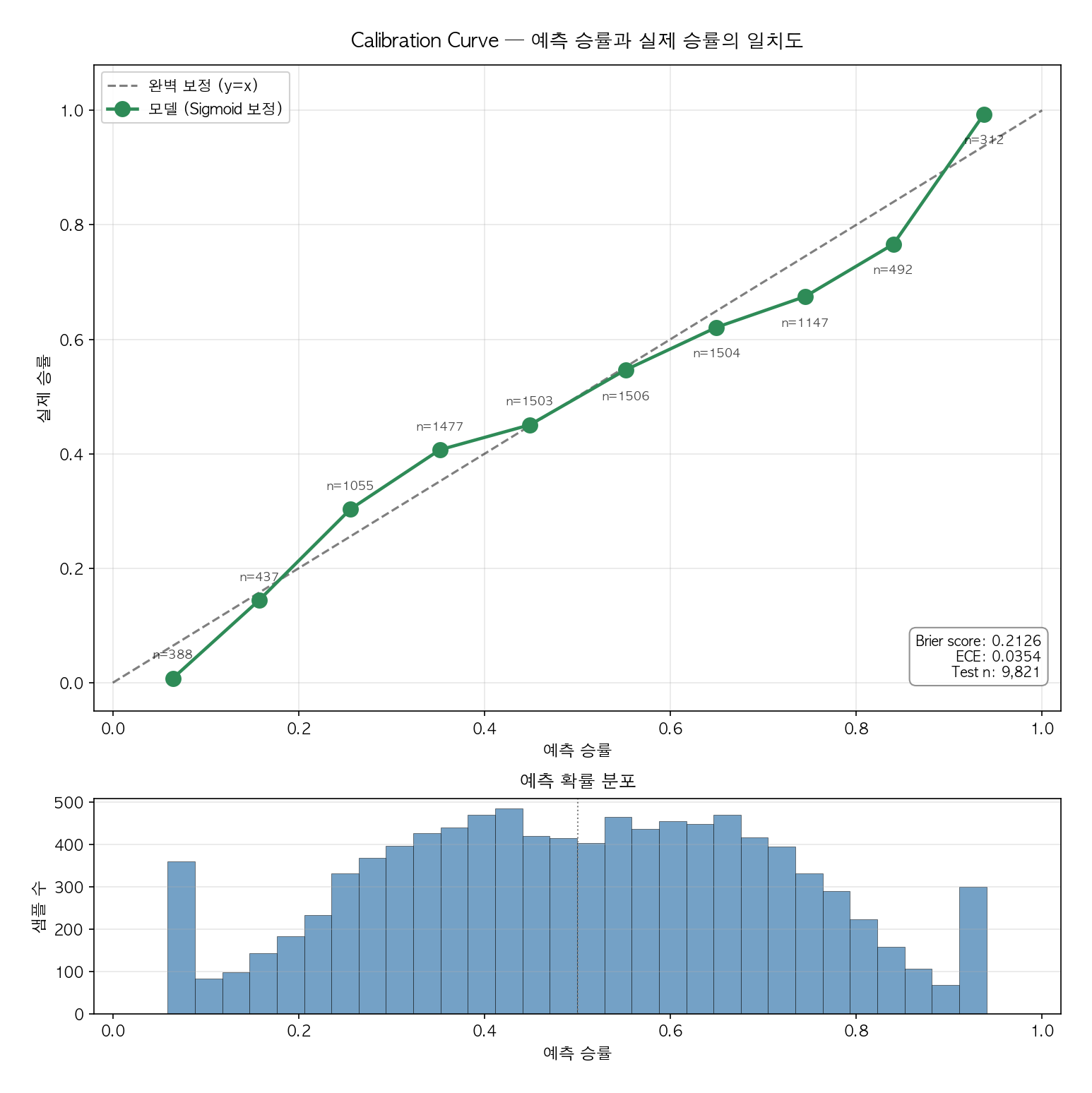
그래프
- 주황 점선 = Sigmoid 보정(ECE 0.0172) / 초록 실선 = Beta 보정(ECE 0.0123) — 현재 모델(2026-07-05)의 raw 예측에 두 보정을 각각 입혀 비교. Beta가 전 구간에서 대각선(완벽보정)에 더 밀착한다. (sigmoid→beta 교체 결정은 2026-06-03; 아래 "왜 교체했나" 참조.)
- 강조된 65–75% 구간에서 Sigmoid는 y=x 아래(과신)였으나 Beta는 대각선에 밀착. 최상위(80%+)의 과소도 함께 해소돼 전 구간 ±3%p 이내.
- 가로축: 모델이 예측한 승률 (0~1을 10개 구간으로 분할)
- 세로축: 각 구간 내 실제 승리 빈도
- 회색 점선 $y = x$: "완벽한 보정". 예측이 곧 실제 빈도와 일치하는 상태.
- 각 점 위의 n=: 해당 bin의 샘플 수
점이 회색선 위에 있으면 모델이 그 구간에서 과소평가(실제 승률이 더 높음), 아래에 있으면 과대평가다. 회색선에 밀착할수록 좋다.
본 모델 결과
- 전 구간에서 점들이 회색선에 근접.
- 실무적으로 "모델이 70%로 예측한 경기는 실제로 약 70% 이긴다"고 읽어도 무리 없는 수준.
하단 히스토그램 해석
보정 곡선 아래의 분포는 예측 확률이 어느 구간에 몰려 있는가를 보여준다. 본 데이터에서는 0.3~0.7 구간의 접전 경기가 지배적이며, 이 분포가 LogLoss의 자연스러운 바닥을 높이는 원인이다. 극단 확률(0.05, 0.95)이 드문 만큼, 그 구간에서의 bin 샘플 수는 적고 보정 점의 통계적 신뢰도도 상대적으로 낮다.
세부 지표의 종합적 해석은 지표 해석 참조.